
並行/多執行緒程式往往會碰上同步問題 (Synchronization),在前一篇文章中介紹了什麼是 Race condition 以及 Critical sections,並且利用互斥鎖將 CS 鎖住。不過,同步問題的解法可不止一個,本篇將探討廣泛應用在 Linux kernel 的 Spinlock。
Spinlock 中文稱做自旋鎖,透過名稱我們就能大概猜到 Spinlock 的功用。與 Mutex 相同,Spinlock 可以用來保護 Critical section,如果執行緒沒有獲取鎖,則會進入迴圈直到獲得上鎖的資格,因此叫做自旋鎖。
原子操作可以確保一個操作在完成前不會被其他操作打斷,以 RISC-V 為例,它提供了 RV32A Instruction set,該指令集都是原子操作 (Atomic)。
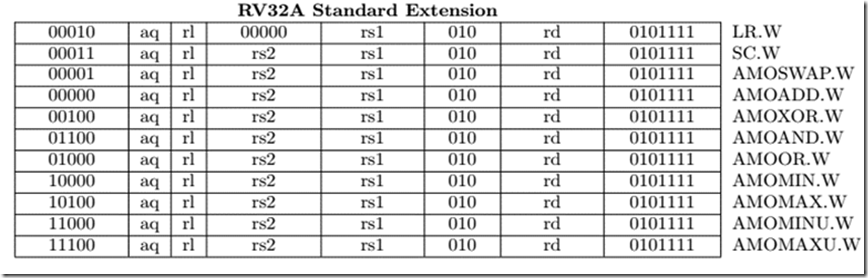
為了避免在同時間有多個 Spinlock 對相同的記憶體做存取,在 Spinlock 實現上會使用到原子操作以確保正確上鎖。
其實不單單是 Spinlock,互斥鎖在實現上同樣需要 Atomic operation。
考慮以下程式碼:
typedef struct spinlock{
volatile uint lock;
} spinlock_t;
void lock(spinlock_t *lock){
while(xchg(lock−>lock, 1) != 0);
}
void unlock(spinlock_t *lock){
lock->lock = 0;
}
透過範例程式碼,可以注意到幾點:
volatile 關鍵字volatile 關鍵字會讓編譯器知道該變數可能會在不可預期的情況下被存取,所以不要將該變數的指令做優化以避免將結果存在 Register 中,而是直接寫進記憶體。xchg(a,b) 可以將 a, b 兩個變數的內容對調,並且該函式為原子操作,當 lock 值不為 0 時,執行緒便會不停的自旋等待,直到 lock 為 0 (也就是可供上鎖)為止。從剛剛的介紹可以得知,執行緒是否能獲取 Spinlock 與投入順序並沒有太大的關係,而是取決於哪一個處理器核心最快查覺到 spinlock 狀態的變化,更精確的說法是,哪個處理器核心的 Cache 更快與主記憶體內容同步。
可參考處理器的快取策略。
Wild spinlock 類似於我們剛剛實作的簡易自旋鎖:
typedef struct spinlock{
volatile uint lock;
} spinlock_t;
void lock(spinlock_t *lock){
while(xchg(lock−>lock, 1) != 0);
}
void unlock(spinlock_t *lock){
lock->lock = 0;
}
不過,這種作法是有明顯的缺陷的,在前面筆者有提到:
執行緒是否能獲取 Spinlock 與投入順序並沒有太大的關係,而是取決於哪一個處理器核心最快查覺到 spinlock 狀態的變化,更精確的說法是,哪個處理器核心的 Cache 更快與主記憶體內容同步。
假設在 8 核心處理器中,如果 8 個核心都希望搶占同一個 lock,便會有些核心始終搶不到 lock,造成 CPU 空轉的現象(瞎忙)。
為了解決這個問題,科學家為 spinlock 添增了搶票的機制,就好比我們去郵局需要領號碼牌。這樣一來,我們就可以確保每個 CPU 都可以獲取到鎖。
struct spinlock {
unsigned short owner;
unsigned short next;
};
void spin_lock(struct spinlock *lock)
{
unsigned short next = xadd(&lock->next, 1);
while (lock->owner != next);
}
void spin_unlock(struct spinlock *lock)
{
lock->owner++;
}
範例程式碼取自 Ref[3]。
其中,xadd(a, b) 也是屬於 x86 的原子操作,它會返回 a 值並將 a + b 的結果寫回記憶體。
當 Owner 等於 spin_lock() 中 next 的值時,也就代表號碼牌叫到該執行緒了,這時候,該執行緒就可以跳出迴圈並進入到 CS,等到結束執行 CS 後,在將 lock 的擁有者交給下一個執行緒。
假設現在有 4 核心的處理器,並且每個核心的執行緒都想要存取 Spinlock,這時候,概念有點像是:
next!=owner,所以進行等待。next!=owner,所以進行等待。next!=owner,所以進行等待。lock->owner 失效了,重新進行了 Cache 並獲得鎖 (next == lock->owner)。貼心提醒: 每個執行緒所持有的 next 值之所以不用考慮 Cache 是否 Valid,是因為在第一次嘗試 lock 時,我們就已經複製一份 next 的值到屬於 Thread 自己的 Stack 囉!
透過上面的解說可以發現: 當搶佔鎖的執行緒一多,就會造成 Cache 被反覆的更新。這樣不止會浪費通道頻寬,更會增加存取速度的延遲。
也因為這樣,電腦科學家又設計了其他 Spinlock 試圖解決這些問題。
MCS spinlock 的示意圖取自 https://static.lwn.net,筆者會再花時間把圖片重做。
為了避免 Cache 被反覆的更新,電腦科學家提出了 MCS spinlock,其設計理念是讓每一個 CPU 各自持有一個 spinlock,每個獨立核心只需要觀察和維護各自的 lock 即可。
參考 lwn.net,MCS Lock 的結構如下方所示:
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; /* 1 if lock acquired */
};
上面提到每個 CPU 都會持有一份 spinlock,不只如此,MCS Spinlock 還會有一個 Main lock 做為這個資料結構的 head。
當 Main lock 被初始化時,其狀態如下圖:
當有 CPU 嘗試獲取鎖時,CPU 會建立一個屬於自己的 MCS spinlock,然後與 Main lock 做原子操作,若 Main lock 的 next 為 Null (Main lock 指向 Null) 的話,代表目前沒有人在排隊,我們就可以讓 Main lock 指向 CPU 持有的 MCS spinlock 然後持有鎖,這邊的原子操作的概念為:
swap(main_lock, cpu_lock){
ret = main_lock;
&main_lock->next = cpu_lock;
&main_lock->locked = &cpu_lock->locked;
return ret;
}
經過原子交換,MCS spinlock 的狀態會變成這樣:

延續剛才的範例,CPU1 已經持有了 spinlock,現在多了一個 CPU2 嘗試存取鎖。經過原子操作,Main lock 會指向 CPU2 持有的 lock :

不過,從 Main lock 的狀態可以看出目前 spinlock 已經被他人佔有 (main_lock->next != null)所以 CPU2 只能等待,這時會將 CPU1 的 MCS lock 指向 CPU2 所持有的 MCS lock :

當 CPU1 完成任務,會對 Main lock 做比較和交換,若 Main lock 指向自己,代表沒有其他人在排隊,便只要更新 Main lock 的 locked 值並讓 Main lock 指向 Null,最後將 CPU1 持有的 MCS spinlock 釋放即可:
除了上述的狀況,如果 Main lock 指向的不是自己,那我們只要將 CPU2 的 locked 值改變,再釋放自身持有的 MCS spinlock :
MCS spinlock 是由 qspinlock 演變而來,有興趣的話可以參考 spinlock 前世今生一文。
既然兩者都是用來將 CS 鎖住,為何還需要這兩個鎖呢?我們可以從其設計思維與運作方法了解這兩個鎖分別適用在哪些場景。
在軟體工程中,忙碌等待是一種以行程反覆檢查一個條件是否為真為根本的技術,條件可能為鍵盤輸入或某個鎖是否可用。忙碌等待也可以用來產生一個任意的時間延遲,若系統沒有提供生成特定時間長度的方法,則需要用到忙碌等待。不同的電腦處理器速度差異很大,特別是一些處理器設計為可能根據外部因素動態調整速率。
-- 維基百科
Spinlock 便是實踐 Busy-waiting 的鎖。
維基百科上並沒有對 Sleep-waiting 做介紹,所以筆者用更簡單的例子說明:
假設我們今天在湯X熊遊樂場,當 A 機台已經有兩個小朋友占用,如果以 Busy-waiting 的方法來看,我們會傻傻的站著等到小朋友玩夠了,才換我們上去玩。而 Sleep-waiting 則是讓我們先去做其他事情,等到小朋友玩夠了再通知我們過去玩。
Mutex lock 便是實踐 Sleep-waiting 的鎖。
首先,由於 mini-riscv-os 是屬於 Single hart 的作業系統,除了使用原子操作以外,其實還有一個非常簡單的作法可以做到 Lock 的效果:
void basic_lock()
{
w_mstatus(r_mstatus() & ~MSTATUS_MIE);
}
void basic_unlock()
{
w_mstatus(r_mstatus() | MSTATUS_MIE);
}
在 [lock.c] 中,我們實作了非常簡單的鎖,當我們在程式中呼叫 basic_lock() 時,系統的 machine mode 中斷機制會被關閉,如此一來,我們就可以確保不會有其他程式存取到 Shared memory,避免了 Race condition 的發生。
上面的 lock 有一個明顯的缺陷: 當獲取鎖的程式一直沒有釋放鎖,整個系統都會被 Block,為了確保作業系統還是能維持多工的機制,我們勢必要實作更複雜的鎖:
typedef struct lock
{
volatile int locked;
} lock_t;
void lock_init(lock_t *lock)
{
lock->locked = 0;
}
void lock_acquire(lock_t *lock)
{
for (;;)
{
if (!atomic_swap(lock))
{
break;
}
}
}
void lock_free(lock_t *lock)
{
lock->locked = 0;
}
其實上面的程式碼與前面介紹 Spinlock 的範例基本上一致,我們在系統中實作時只需要處理一個比較麻煩的問題,也就是實現原子性的交換動作 atomic_swap():
.globl atomic_swap
.align 4
atomic_swap:
li a5, 1
amoswap.w.aq a5, a5, 0(a0)
mv a0, a5
ret
在上面的程式中,我們將 lock 結構中的 locked 讀入,與數值 1 做交換,最後再回傳暫存器 a5 的內容。
進一步歸納程式的執行結果,我們可以得出兩個 Case:
lock->locked 為 0 時,經過 amoswap.w.aq 進行交換以後,lock->locked 值為 1,回傳值 (Value of a5) 為 0:void lock_acquire(lock_t *lock)
{
for (;;)
{
if (!atomic_swap(lock))
{
break;
}
}
}
當回傳值為 0,lock_acquire() 就會順利跳出無窮迴圈,進入到 Critical sections 執行。 2. 沒有獲取鎖
反之,則繼續在無窮迴圈中嘗試獲得鎖。
在介紹完 Spinlock 、 Mutex 與 Spinlock 的差別後,筆者再補充一下這兩個鎖適合應用在哪些場景:
BTW: 學習 spinlock 時不難發現在 Linux 中真的使用了大量的 Linked-list,學習並行程式的同步問題之餘還能看到多個 Linked-list 的延伸,可以說是一石二鳥(嗎)。


 iThome鐵人賽
iThome鐵人賽